Data science is rapidly advancing and powering the Data SuperCycle.-> The Data SuperCycle like other economic SuperCycles will persist for a long time. Some supercycles have extended well over three decades.
We believe that the world is in the early stages of the Data SuperCycle, which begs the question: When did it begin? Fundamentally the Data SuperCycle relies on data infrastructure and data analysis tools to create value from proprietary (unstructured) data to feed its momentum. At DYDX Capital we think that the evolution of analysis tools is the greatest influence in creating and maintaining the SuperCycle. We tried to track this evolution over time to understand how it evolved and what runway it might have.
To do this our team at DYDX Capital analyzed the time point when different waves of data science technology experienced an inflection. Our approach was to measure the usage of key terms associated with data analysis in databases from the academic literature, start-up company data repositories and web traffic datasets. At DYDX Capital we included the broad term “data science” as well as “machine learning”, “ML”, “deep learning”, “AI”, and “LLM” among others. Using “data science” as a starting point we saw a large inflection in usage around 2014. This moment had been building on the back of a strong and growing interest in data science which began around 2010 and centered on big data. Consequently, we mark 2014, when we observe the tipping point, as the very beginning of the Data SuperCycle. A couple of years later, over 2016-2017, we see an inflection for “machine learning” and then a few years later we see AI take off (2019) culminating in 2022 with the release of ChatGPT and its underlying LLM.
–> Data Source: PubMed & arXiv Databases
“We think that a new technology wave is imminent”
While the timepoints can no doubt be moved a year or two, overall, we believe that the very beginning of the Data Supercycle was close to the year 2014. At DYDX Capital, we also think that there is an interesting, nested technology cycle of 2-3 years for new data analysis technologies to hyper-evolve. It appears that there is a complex interplay between data availability and type that understandably shapes data science advances. While the world does not fully understand this sub-cycle, at DYDX Capital we think that a new technology wave is imminent. Already over 2024, with the increase in reasoning-based AI models, perhaps it is well underway. Most importantly we think that even though the Data SuperCycle may have begun 10 years ago it has many, many years before its likely peak. It is a macro-economic driver that will persist for decades and at DYDX Capital we are excited about riding this wave into the future.





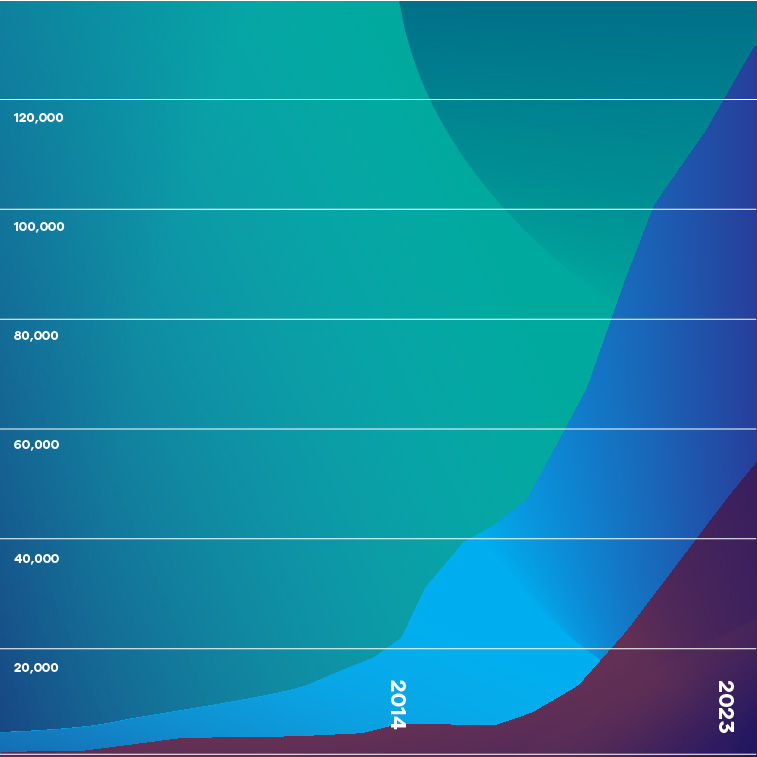 –> Data Source: PubMed & arXiv Databases
–> Data Source: PubMed & arXiv Databases 