A shift in the status quo.-> Previously at DYDX Capital, we’ve discussed the Data SuperCycle and highlighted its drivers. Amongst these are technology shifts and infrastructure investments which synergistically act to extract insights from data.
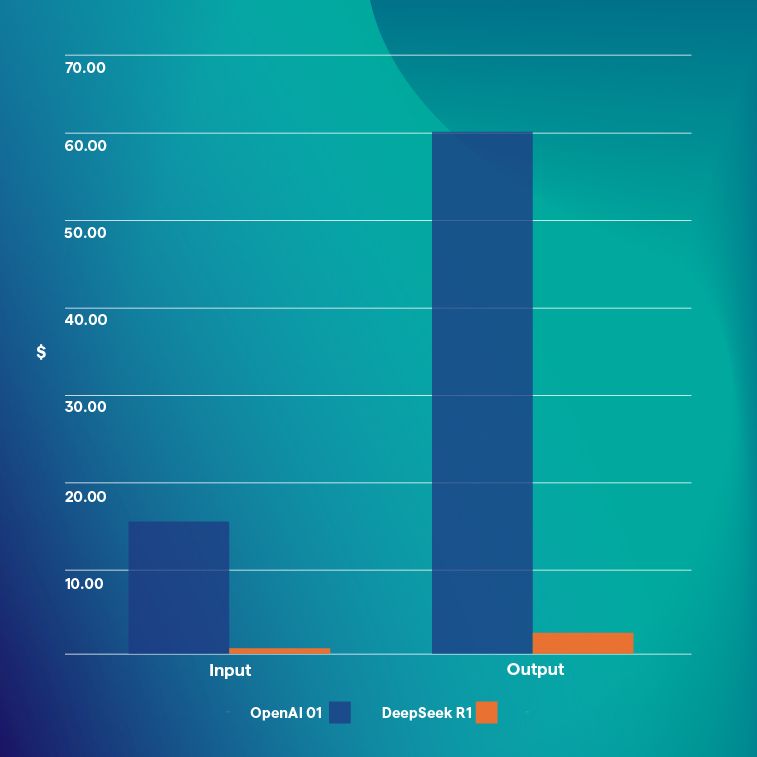
In turn, these insights birth world-beating products that improve the human condition. One such shift that we are all familiar with was the release of ChatGPT in 2022. This allowed new datasets to be interrogated and spurred the massive increase in generative AI and agentic AI companies. It also went hand-in-hand with vast spending on GPUs to power the models. It was a brute force approach to model improvement which incrementally cost much more with scaling. This isn’t a new phenomenon and we’ve seen something similar with many exponential optimization curves, such as those in biology and chemistry. Then, all of a sudden, the release of DeepSeek’s R1 model caused a massive shock to the relative status quo that had set in between the main players (NVIDIA and OpenAI/Anthropic/xAI). The disruption to this steady state of value capture between the incumbents worried investors – especially those that had a more one-dimensional, “all-in on AI”, thesis. At its core, this was the result of the open-source R1 being more than 25x cheaper than OpenAI for customers across data input and data output which meant that value would likely move from the incumbents, and possibly move quite rapidly.
“We are going to see continued leaps in supply, unlocking massive warehouses of data”–> At DYDX Capital we have been purposeful in defining the economic opportunity in terms of data.
We did this because we have seen many times before that although infrastructure (GPUs) and new tools (OpenAI’s models for instance) can capture huge value (a worthwhile investment target) the durable and large opportunity is investing in the companies that these enable. Data-driven companies are also an expanding universe of opportunity since an expensive new technology often forces innovation to find cheaper approaches increasing the use cases and market size – an expansion that might result from DeepSeek’s release of R1.
This was not a surprising outcome. Indeed previously, in discussing the Data SuperCycle, we reported a nested innovation cycle that drove the hyper evolution of data science: it suggested a new advance was imminent. DeepSeek’s R1 certainly fits the bill of being the next jump forward predicted by the innovation cycle. The net result of these technological advances is to reward the companies with novel and proprietary data. To that end the massive decrease in price for input/output tokens means that consumption of these tools can increase significantly.
Fundamentality this will further push the Data SuperCycle forward as even more proprietary data is analyzed. Over the coming months and years many more advances will increase the capability of AI models as well as decrease the associated costs. Simply put, we are going to see continued big jumps in supply unlocking a massive warehouse of demand (data). At DYDX Capital we are excited to see what next model or technology will create a non-linear shock to drive the Data SuperCycle to new heights.